在人工智能“泛滥”的今天,仍然会有各种各样的问题对这一人类当前最具前景的技术构成威胁,在近日 Google Brain 研究人员 Ian Goodfellow 等人的最新论文《Adversarial Examples that Fool both Human and Computer Vision》中,他们就举出了其中的一个代表——对抗样本。
论文地址:https://arxiv.org/abs/1802.08195
对抗样本指的是攻击者故意设计的,会让机器学习模型作出错误决定的输入。机器学习很容易受到对抗样本的攻击,比如,即使是小小的扰动,就可以让计算机视觉系统将校车误认为是鸵鸟。但是人类视觉系统是否会被其干扰仍是一个悬而未决的问题。

图丨对图片加上小小的扰动,使得猫的图片变得像狗
机器学习和脑科学的研究一直相辅相成。比如,在科学家设计出物体识别算法之前,他们就坚信这是一定可以做到的,因为人类的大脑是可以识别出物体的。因此,如果我们可以证明,人脑可以抵抗特定种类的对抗样本的干扰,那么这将证明机器学习中也会有相似的机制。而如果人脑的确会被对抗样本愚弄,那么我们就应该放弃机器学习中抵抗对抗样本的努力,转而去设计那些尽管包含了非鲁棒性的机器学习组建却仍然安全的系统。
在计算机视觉领域,对抗样本通常是对数据集中的样例图片加以扰动得到的新图片。这种扰动不同于噪音,而是根据模型精心设计的。许多流行的生成对抗样本的算法依赖于模型的结构和参数来完成对输入基于梯度的优化。由于人类视觉系统的结构和参数等均是未知的,因此这些方式可能无法生成可以用于人类视觉识别的对抗样本。

图丨在对抗样本的影响下,大熊猫被识别为长臂猿
对抗样本通常从一个模型向另一个模型转换,使得它可以攻击结构未知的模型。而人类是否会受这样的对抗样本的影响就成了一个问题。显然,人类的视觉认知系统有许多偏见,而且会产生光学上的幻觉。但是这和对自然图片加以扰动非常不同。因此,我们通过三个主要的想法来测试,对抗样本会对人类视觉系统产生可见的影响。
1. 利用黑箱对抗样本生成技术,它在不能了解参数和结构的情况下对目标模型构建对抗样本。
2. 通过改变机器学习模型来模仿人类视觉的原始过程,使得对抗样本更可能转化为适合人类观察者的。
3. 评估人类观察者在给定时间内做出的分类决策,使得人类知觉的细微影响都可以被探测到。因为人类在分类任务上的准确率接近完美,因此微小的改变可能无法在准确率上有所反应。而只对图片进行简短的展示,即使清晰的图片,人类也无法再达到完美的准确率,因此微小变化产生的影响得以在准确率上有所体现。
对抗性问题的目的是导致一个错误的决定。但是当进行扰动后,很多图片失真,已经不再是一个真正的实际存在的景象,此时很难定义对这个并非真正物体的照片的分类。因此在这项实验中,只进行微小的扰动,并对扰动的图片按照之前的类别进行分类。但对扰动后的图片的分类问题仍值得进一步讨论探究。
实验中使用了 ImageNet 中的图片,并将其中的六类图片分成三组:宠物类、危险类和蔬菜类。最近的研究已经发现了深度卷积神经网络和灵长类动物的视觉系统之间的相似性,因此使用这些图片来训练不同的 CNN 模型来模拟人类视觉过程。

图丨实验过程:主体坐在光线暗的房间中距离高刷新率电脑屏幕 61cm 的地方。主体被要求通过按按钮将屏幕上出现的图片分到给定的两个类别中的一个。图片先在屏幕上固定出现 500-1000ms,然后一张 15.24 cm × 15.24 cm 的图片出现在屏幕中央 63ms,然后图片被十个随机的二维码遮盖,每个 20ms,结束后有 2200~2500ms 的时间做出分类的选择。
每个实验只包括一个组别。在每个组中,图片以下列四种形式之一展示:
1.image :来自 ImageNet 的图片。
2.adv:添加了扰动的 image。
3.flip:添加了经过垂直变换的扰动的 image。
4.false:强制主体犯错误的条件。使用较大的扰动,使得出现的图片不属于可以选择的任何一类。因为扰动对观察者产生的影响,可能只是因为降低了图片的清晰度。加入这个准确率为 0 的条件,可以检验扰动是否会影响观察者所作出的错误的选择。

图丨不同扰动方式对图片进行处理
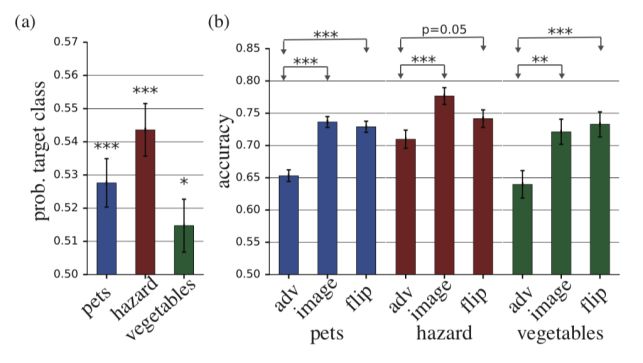
图丨 (a) 选择不同扰动目标类别的概率(b)正确分类的准确率
从图表中可以发现,加入了扰动的 adv 种类的分类准确率远低于 image。同时 adv 类别的准确率也远低于 flip。这说明扰动与特定图片的组合对分类的影响,与人类区分物体时所感知的特定特征相关。
实验结果发现,通过计算机视觉模型转化的对抗样本,确实会影响人类观察者的准确性。这一研究也引出了更多的基础性问题。CNNs 网络在生成对抗样本这一过程中所起的作用,是否和它与人脑视觉机理的相似性有关?对抗样本的哪些性质对人类的认知产生了作用?这些性质与现实世界又有什么关系?这些问题的研究都极富价值,并会推动我们进一步理解人脑和深度神经网络的奥秘。
-End-
编辑:王维莹
参考:Adversarial Examples that Fool both Human and Computer Vision 返回搜狐,查看更多
责任编辑: