作者:Reuben Feinman等
参与:黄小天、刘晓坤、许迪
借助先验知识,也就是归纳偏置,人类得以有效学习关于世界的新知识。本文发现,简单神经网络在观察 4 个物体类别的 3 个实例之后,便可以发展出一种形状偏置,这预示着神经网络开始快速学习词汇,与儿童的认知发展过程相一致。本文启发了一种参考生物认知发展过程以初始化模型,然后逐渐泛化到更复杂数据集的模型开发范式。
借助先验知识,也就是归纳偏置,人类得以有效学习关于世界的新知识。本文发现,简单神经网络在观察 4 个物体类别的 3 个实例之后,便可以发展出一种形状偏置,这预示着神经网络开始快速学习词汇,与儿童的认知发展过程相一致。本文启发了一种参考生物认知发展过程以初始化模型,然后逐渐泛化到更复杂数据集的模型开发范式。
论文:Learning Inductive Biases with Simple Neural Networks

论文链接:https://arxiv.org/pdf/1802.02745.pdf
摘要:为了高效学习新概念,人类大量使用关于世界的先验知识。这些先验——也被称作「归纳偏置」(inductive biases)——归属于学习器的内部模型空间,可帮助学习器做出超出已观察数据之外的推断。最近一项研究发现,针对目标识别而优化的深度神经网络可以发展出形状偏置(Ritter et al., 2017),一种在儿童早期词汇学习之中扮演重要角色的归纳偏置。然而,这些神经网络使用了大量的训练数据,并且这些偏置发展所需的条件也很不清晰。此外,上述网络的学习机制如何与儿童发育过程相关尚不清楚。我们使用抽象模式和合成图像的可控数据集来研究神经网络中形状偏置的发展和影响,使得我们可以系统地改变提供给学习算法的经验数据的数量和形式。我们发现简单神经网络在观察 4 个物体范畴的 3 个实例之后就发展出一种形状偏置。这些偏置的发展预示着网络开始快速学习词汇,这与儿童的认知发展过程相一致。

图 1:形状偏置泛化测试。(a) 中的第一阶测试评估儿童是否能够根据形状学习把一个熟悉的物体名称泛化到一个新示例。这是发展形状偏置的第一步。(b) 中的第二阶测试评估儿童是否可以根据形状把一个新名称泛化到一个新示例。这是发展形状偏置的第二步,也是最后一步。
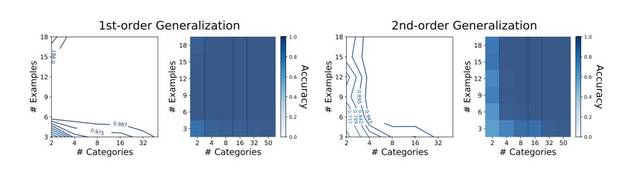
图 2:使用不同训练集大小训练的显式形状偏置的 MLP 泛化结果。x 轴和 y 轴分别表示提供给网络的类别数量和每个类别的示例数量。图中展示了超过 1000 次特定泛化测试的准确性,由 10 次训练运行结果取平均值得到。同一数据分别以等高线和热图展示。

图 3:多层感知机架构。形状、颜色、纹理属性向量被集合并馈送至一个 30 单元的隐藏层,后面是一个分类层。图中展示了 3 个实例输入物体(每次只向网络输入一个物体)。

图 4:感知相似性,作为物理刺激距离的函数。测试刺激根据形状或颜色维度被系统地改变。在每种情况下,通过最后一个隐藏层的特征计算原始刺激与其变化的对应物之间的网络相似性分数。

图 5:实验 2 的训练刺激。(a) 中是不同形状和颜色的新物体(前三个输入通道)。(b) 是一些可在第 4 个输入通道中发现的纹理实例。
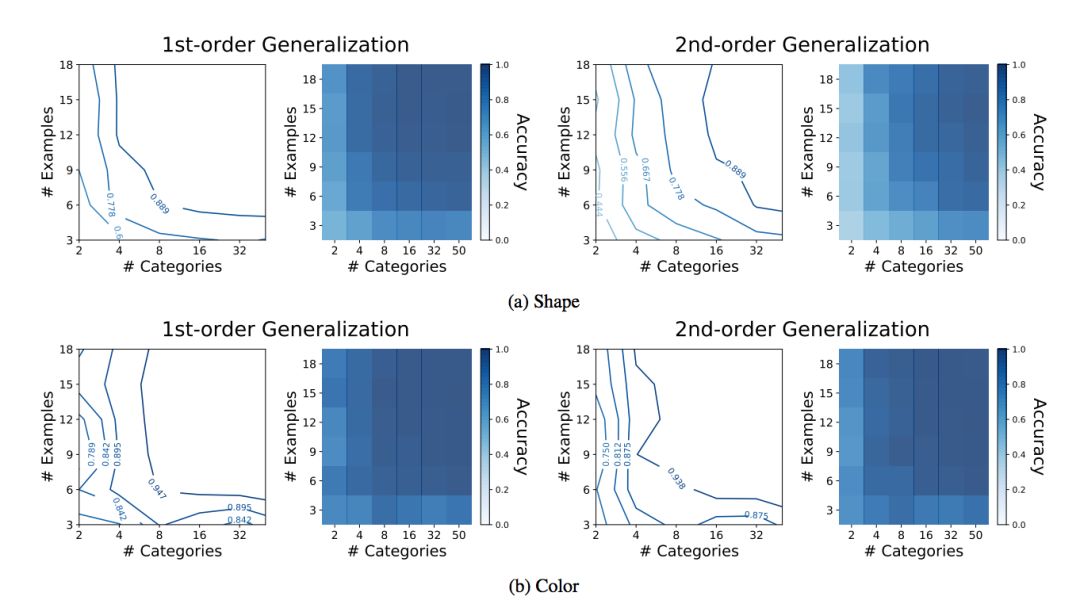
图 6:CNN 泛化结果。(a) 展示的是显式形状偏置训练的结果,如实验所述。为了对比,(b) 展示的是一个被训练用来基于颜色标注物体类别名称的神经网络的结果。在这一案例中,泛化测试评估颜色匹配被选择的次数比例。每一网格的结果展示 10 次训练运行的平均值。

图 7:卷积网络架构。该网络接收 4D 图像刺激并被训练基于形状使用类别名称标注图像中的物体。

图 8:可视化已学习的首层卷积核的 RGB 通道。(a) 中是我们的 CNN(由显式形状偏置 (N=50 & K=18) 进行训练)卷积核。每行对应于 5 个卷积核之一。前 3 个通道分别展示了 R、G、B 列。这 3 个通道一起合并为第 4 列,标注为 RGB。(b) 中是我们的 CNN(被训练根据颜色标注物体的类别名称)的镜像卷积核。在 (a) 和 (b) 中,只展示了通道 4 的通道 1-3。
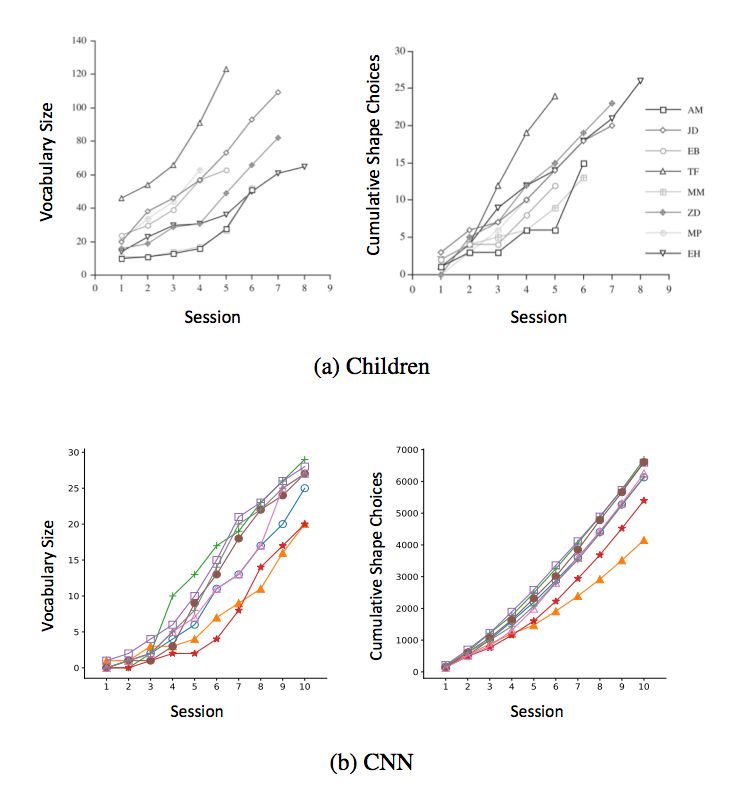
图 9:形状偏差与词汇的学习曲线。(a) 展示的是 GershkoffStowe & Smith (2004) 研究中 8 个儿童参与者的学习曲线。参与者将学习 5-8 个实验环节。曲线展示的是词汇大小(左)和累加形状选择(右)。这里的词汇包括所有的名词类型。(b) 是 CNN 网络的在类似问题上的绘图。出于可视性考虑从总共 20 个神经网络中随机选择 8 个。这里,词汇仅针对基于形状的物体名称进行测量。
综合讨论
通过一组可控的综合实验,本论文提供了有关允许在神经网络中 learning-to-learn 的环境条件的新见解。在 Colunga & Smith (2005) 的工作基础之上,我们表明简单神经网络可从 4 个类别的 3 个实例的抽象模式的刺激之中学习形状偏置。因此,这些网络在偏置发展所需的样本复杂性中同时采用 HBMs 和人类儿童的方法。通过扩展 Ritter et al. (2017) 的研究成果,我们表明通过高维彩色图像训练的简单 CNN 架构可以通过 8 个目标类别的 6 个实例学习形状偏置,然而不是所有的刺激属性都相同。我们的彩色图像训练实验表明 CNN 的学习动态取决于其训练时接受的属性。这一结果凸显了把刺激扩展到更多复杂数据的重要性,其中不同刺激属性有不同的物理性质。最后,我们的新结果表明一个已训练网路对形状的敏感性如何随着输入而变化参数。
在最近的一项研究中,Hill et al. (2017) 训练一个神经网络智能体导航虚拟 3D 环境,并使用类似于我们的简化人工物体刺激根据基于名称的语言指令收集物体。作者从有关人类儿童的研究中获得启发,其结果值得注意。然而,我们的工作目标在某些重要方面很不同。本实验中的智能体一起接收视觉和语言的联合输入,并且必须输出导航决策。因此网络被要求同时学习不同的任务——即,视觉感知、语言理解和导航。因此论文的学习曲线反映了一种多方面学习的形式。本论文中我们的主要兴趣是研究神经网络学习归纳偏置所需的精确数据量。我们的框架旨在独立研究这一问题,以最大限度地减少外部因素的干扰。
人类儿童的形状偏置的发展据知与改进的单词学习能力相关联,这一现象在我们的网络之中有所反映。这一发现说明,有可能将模型通过形状偏置训练进行初始化之后,可能更加高效地训练大规模图像识别模型。在未来的工作中,我们希望通过本文启发的初始化框架,在 ImageNet 一般规模的 DNN 中验证这一假设。
本文为机器之心编译,转载请联系本公众号获得授权。返回搜狐,查看更多
责任编辑: